PDF Extraction
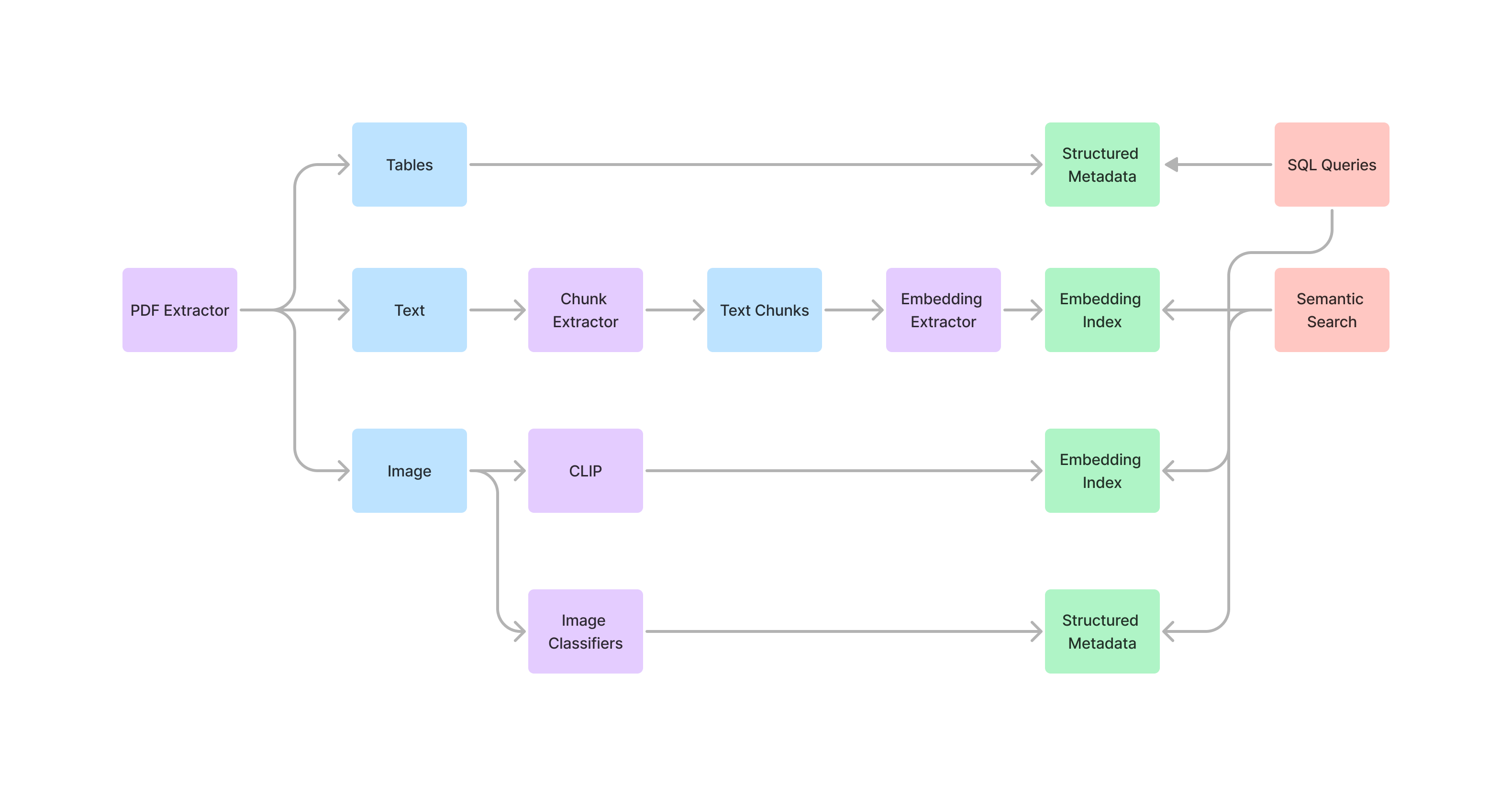
Indexify provides extractors that extract text, images, and tables from PDF documents. Some extractors also convert PDFs to markdown documents. You can build complex pipelines that can extract and write tabular information from PDF documents in structured stores or extract embedding from texts in the documents. PDF is a complex document type; we offer many different extractors suitable to various use cases.
What Can You Achieve with Indexify?
With Indexify, you can accomplish the following with your PDFs:
- 🔍 Data Extraction: Easily extract specific information from PDFs, such as fields from tax documents, healthcare records, invoices, and receipts. Use Cases: Automate Manual Data Entry
- 📚 Document Indexing: Build searchable indexes on vector stores and structured stores by combining PDF extractors with chunking, embedding, and structured data extractors. Use Cases: RAG Applications, Assistants, etc.
- 🤖 Document Q&A: Get Answers to specific Questions from Documents without creating indexing.
The Extraction Pipeline: A Three-Stage Process
PDF Extraction Pipelines are usually composed of three stages. You can use one or more of these stages depending on your use case -
- Content Extraction Stage: Start by extracting raw content from your PDFs using extractors like
pdf/pdf-extractororpdf/markdown. These extractors will retrieve text, images, and tables from your documents. - Content to Chunk Extraction Stage: Break down the extracted content into manageable chunks using extractors like
text/chunking. This stage helps organize your content into coherent and contextually relevant pieces, making it easier to process and understand. - Chunk to Embedding Extraction Stage: Convert the chunks into vector embeddings using extractors like
embedding/minilm-l6orembedding/arctic.
Image Extraction
If you would like to extract images from PDF, the best extractor to use is tensorlake/pdf-extractor It automatically extracts images from documents and writes them into blob stores. Once images are extracted, you could create pipelines for many downstream image tasks - Embedding using CLIP for semantic search, visual understanding of images using GPT4V, Cog or Moondream, or object detection using YOLO.Indexify provides extractors for all these downstream tasks.
You can get extracted images from pdf-extractor with a simple python code like this:
def get_image_content(client, content_id):
extracted_content = client.get_extracted_content(content_id)
for item in extracted_content:
child_id = item['id']
structured_data = client.get_structured_data(child_id)
for data in structured_data:
if 'metadata' in data and data['metadata'].get('type') == 'image':
return item['content']
return None
Table Extraction
Tables are automatically extracted by tensorlake/pdf-extractor as JSON metadata. You can query the metadata associated with documents by calling the Retrieval APIs.
You can get extracted tables from pdf-extractor with a simple python code like this:
def get_table_content(client, content_id):
extracted_content = client.get_extracted_content(content_id)
for item in extracted_content:
child_id = item['id']
structured_data = client.get_structured_data(child_id)
for data in structured_data:
if 'metadata' in data and data['metadata'].get('type') == 'table':
return item['content']
return None
Explore the PDF Extractor Landscape
We offer a wide range of PDF extractors to suit specific use-cases. Whether you're dealing with invoices, scientific papers, or scanned documents, we've got you covered. Here's a quick overview of our extractor lineup:
| Extractors | Output Type | Best For | Output Example |
|---|---|---|---|
| tensorlake/layoutlm-document-qa-extractor | metadata | Invoices Question Answering | [Feature(feature_type='metadata', name='metadata', value={'query': 'What is the invoice total?', 'answer': '$93.00', 'page': 0, 'score': 0.9743825197219849}, comment=None)] |
| tensorlake/pdf-extractor | text, image, table | Scientific Papers with Tabular Info | [Content(content_type='text/plain', data=b'I love playing football.', features=[Feature(feature_type='metadata', name='text', value={'page': 1}, comment=None)], labels={})] |
| tensorlake/ocrmypdf | text | Photocopied/Scanned PDFs on CPU | [Content(content_type='text/plain', data=b'I love playing football.', features=[Feature(feature_type='metadata', value={'page': 1}, comment=None)], labels={})] |
| tensorlake/easyocr | text | Photocopied/Scanned PDFs on GPU | [Content(content_type='text/plain', data=b'I love playing football.', features=[Feature(feature_type='metadata', name='text', value={'page': 1}, comment=None)], labels={})] |
| tensorlake/marker | text, table | Detailed structured & formatted PDF | [Content(content_type='text/plain', data=b'I love playing football.', features=[Feature(feature_type='metadata', name='text', value={'language': 'English', 'filetype': 'pdf', 'toc': [], 'pages': 1, 'ocr_stats': {'ocr_pages': 0, 'ocr_failed': 0, 'ocr_success': 0}, 'block_stats': {'header_footer': 2, 'code': 0, 'table': 0, 'equations': {'successful_ocr': 0, 'unsuccessful_ocr': 0, 'equations': 0}}, 'postprocess_stats': {'edit': {}}}, comment=None)], labels={})] |
Get Started with PDF Extraction
You can test it locally:
-
Download a PDF Extractor:
-
Load it in a notebook or in a Python script:
Continuous PDF Extraction for Applications
We've made it incredibly easy to integrate Indexify into your workflow. Get ready to supercharge your document processing capabilities!
-
Start the Indexify Server:
-
Start a long-running PDF Extractor:
-
Create an Extraction Graph:
from indexify import IndexifyClient client = IndexifyClient() extraction_graph_spec = """ name: 'pdfknowledgebase' extraction_policies: - extractor: 'tensorlake/pdf-extractor' name: 'my-pdf-extractor' """ extraction_graph = ExtractionGraph.from_yaml(extraction_graph_spec) client.create_extraction_graph(extraction_graph) -
Upload PDFs from your application:
-
Inspect the extracted content:
With just a few lines of code, you can use data locked in PDFs in your applications. Example use-cases: automated data entry, intelligent document search, and effortless question answering.
Explore More Examples
We've curated a collection of inspiring examples to showcase the versatility of PDF extraction. Check out these notebooks:
- Efficient and supercharged RAG for mixed context texts with Indexify's framework, Gemini's 1M context & Arctic's embeddings
- Question Answering from PDF using Indexify and OpenAI
- Schema based HOA Documents
- Multi-state Terms Documents
- Scientific Journals
- SEC 10-K docs
- Entity Recognition from PDF using Indexify and Gemini
- Invoices: Extract and analyze invoice data like a pro!
- Terms and Condition Documents of Car Rental: Navigate the complex world of car rental agreements with ease.
- Terms and Conditions Documents of Health Care Benefits: Demystify health care benefits and make informed decisions.