Fast Extraction Pipelines and Retrieval for AI Applications at Any Scale
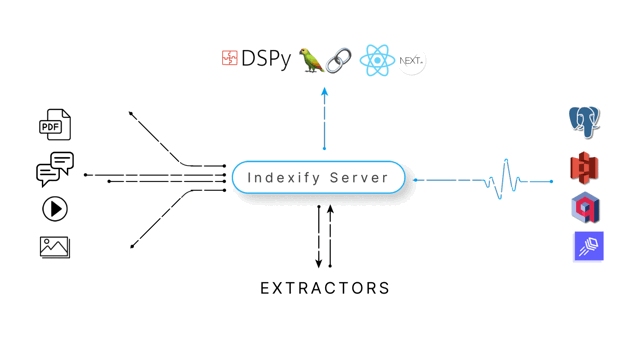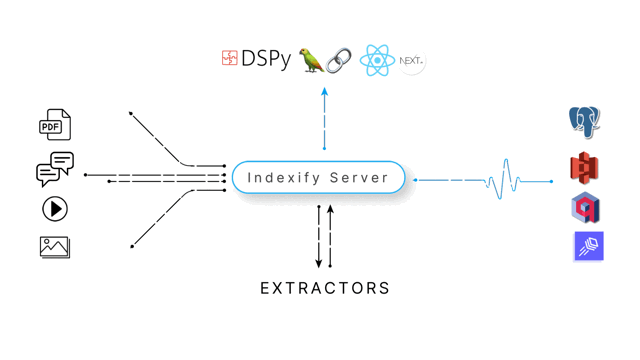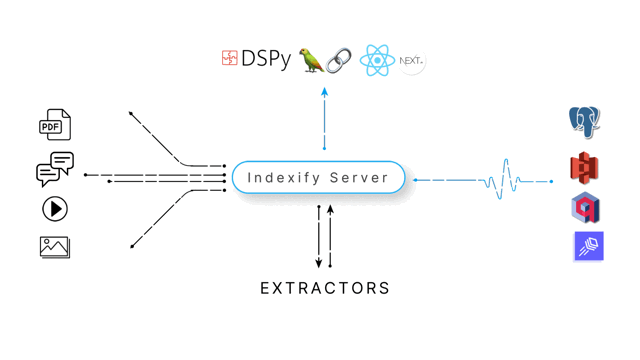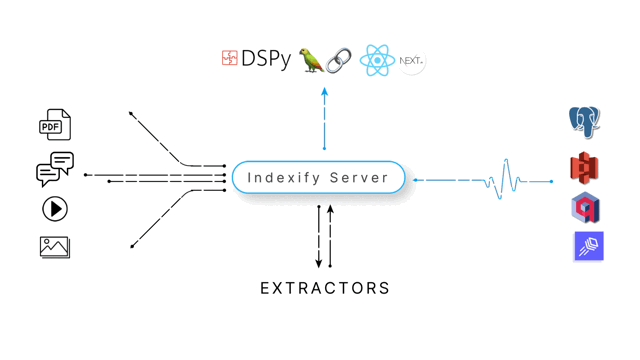
Indexify helps you build complex distributed data pipelines that scale from a demo to billions of users by changing a single line of configuration. With Indexify, you'll be able to have
- Insights from Unstructured Data : Run state of the art models efficiently to transform unstructured data into structured data
- Fault Tolerant Pipelines: Effectively distribute workloads without worrying about network failures, automatic retries or scaling
- Full Observability: Every step of the pipeline can be queried with SQL, Semantic Search or both
- Automatic Reindexing: We track all updates to your data in real time, causing any changes to trigger an automatic update of all computed values.
Why Use Indexify
Building a data-intensive product with LLMs often involves -
- Ingesting new data, extracting structured information, or embedding and writing them to storage.
- Setting up fault tolerant pipelines to do the ingestion-extraction process continuously as new data is generated by humans or business processes.
- Running compute intensive models for extraction efficiently in pipelines.
- Serving fresh data by searching vector indexes and structured stores to LLMs for making accurate decisions.
While there are many data frameworks for unstructured data, they are primarily optimized for prototyping applications locally. Reliable data infrastructure for production use cases is designed to be distributed on many machines to allow scale-outs, fault-tolerant to hardware or software crashes, predictable latencies and throughput, and observable to help troubleshoot.
Indexify runs locally without any dependencies, making it easy to build applications and test and iterate locally. It does so without sacrificing the properties that make data systems shine in production environments. Applications built with Indexify can run on laptops and can run unchanged in production. Indexify can auto-scale, is distributed, fault-tolerant, and is fully observable with predictable latencies and throughput.
Start Using Indexify
Dive into Getting Started to learn how to use Indexify.
If you would like to learn some common use-cases -
- Learn how to build production grade RAG Applications
- Extract PDF, Videos and Audio to extract embedding and structured data.
Features
- Makes Unstructured Data Queryable with SQL and Semantic Search
- Real Time Extraction Engine to keep indexes automatically updated as new data is ingested.
- Create Extraction Graph to create multi-step workflows for data transformation, embedding and structured extraction.
- Incremental Extraction and Selective Deletion when content is deleted or updated.
- Extractor SDK allows adding new extraction capabilities, and many readily available extractors for PDF, Image and Video indexing and extraction.
- Multi-Tenant from the ground up, Namespaces to isolate sensitive data.
- Works with any LLM Framework including Langchain, DSPy, etc.
- Runs on your laptop during prototyping and also scales to 1000s of machines on the cloud.
- Works with many Blob Stores, Vector Stores and Structured Databases
- We have even Open Sourced Automation to deploy to Kubernetes in production.